
2020 was the year in which dematerialisation became a central aspect of people’s and companies’ activities, thus consecrating the centrality of digital information. Today, more than ever, data is the most valuable commodity, and it has become so many and so complex that a new term is needed to identify it: Big Data.
Although the term Big Data has become so overused, it is useful for those who deal with innovation and digitalisation to understand the real state of the art regarding the processing of large amounts of data and the trends expected in this field for 2021.
First of all, a definition of Big Data is a must, also because the term is often misused, simply as a synonym for big amount of data.
In fact, this refers to huge amounts of data (Terabytes but also Petabytes and more) spread over several servers, often in different companies and in different formats (Databases, files…). In addition to the number and volume of data, factors such as speed, variety, veracity and value come into play to make data ‘big’.
A conventionally agreed definition of Big Data is provided by the McKinsey Global Institute, which identifies it as: “A system that refers to datasets whose volume is so large that it exceeds the capacity of relational database systems to capture, store, manage and analyse”.
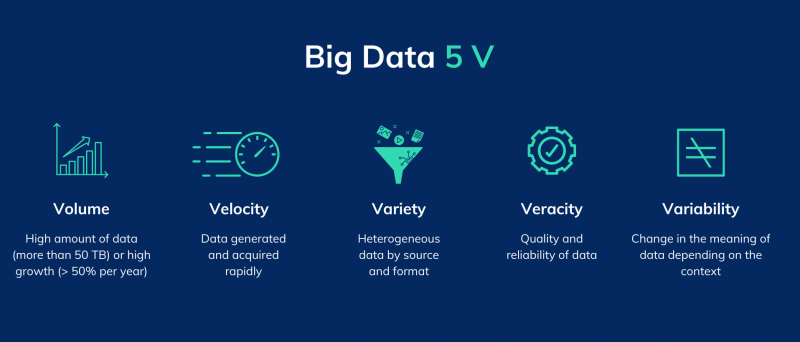
In 2001, Doug Laney, then Vice President and Service Director of Meta Group, described in a report the 3V Model for defining new data, generated by the increase in information sources and the evolution of technologies such as Volume, Velocity and Variety which over time has been enriched with Veracity and Variability. For companies, these are therefore complex to manage, requiring high levels of expertise and high costs.
Big Data for business
In terms of using Big Data to increase the quality of business analysis, the most important activity is to implement and automate the data preparation to convert data into usable information.
A complete repository of Big Data needs to be refined, aggregated and/or analysed before it can be used and shared.
As far as data aggregation is concerned, it is a simple and well-known concept that is equivalent to bringing the concept of pivot tables to a much larger and more complex database.
As far as analysis is concerned, the choice between numerous techniques, from artificial intelligence to standard statistical surveys, varies according to the objectives to be achieved and the type of information to be extracted from the data. At this stage of the process, the decision lies with the analyst.
The process of refining the repository, on the other hand, refers to the correction of the data contained in the database, but also to the activity that leads to standardising the nature of the information to make it truly usable. Having data in many different servers and formats makes any analysis complex.
Data refinement
Some many algorithms and platforms help companies to adjust their data. This process seems to be one of the biggest Big Data challenges of 2021. Even if developments and innovations focus more on the analysis part, which is more impactful because it can provide a tangible result, it is often underestimated that to get the right result, it is necessary to start with data that is really ready to be analysed.
Many companies decide to start data analysis projects (Big Data or not), but they don’t check the quality of their databases before. The focus should therefore be on optimising this aspect, sometimes delaying
the final result, but safeguarding the quality of the analysis output.
But, what does it mean in detail to refine one’s own repository? Very often the data you have at your disposal contain certain imperfections that make it difficult to use them:
- Duplications
- Non-unique keys
- “Dirty” characters such as spaces in places where there should be none
- Different formats of the same data in different sources (e.g. two databases dealing with numbers with a comma with a different number of decimal places)
- …
For all these issues, it is worth investing time and resources in automating the cleaning process.
Another issue of growing interest is the creation of repositories able to store data from different sources in a single output (or even more than one, as long as the quantity is reasonable).
Assuming that most realities collect their data on different databases, servers and files, which are developed according to different languages and logics, different skills are required to standardise the output data. There are tools available on the market, both cloud-based and not, that allow managing heterogeneous repositories, but they still have some limitations in terms of accuracy of the result, costs and timing.
In the future of artificial intelligence and other techniques, this activity will play an increasingly central role and will require new developments and automation.