
La Cluster Analysis è ad oggi uno degli strumenti più utilizzati da Data Analyst e Data Scientist per ottenere indicazioni fondamentali, ma semplificate, a partire da grandi moli di dati. Il termine cluster, di per sé, sta a indicare un raggruppamento di oggetti che hanno una o più caratteristiche in comune.
In sostanza, preso come riferimento un insieme di oggetti aventi un certo numero di attributi, questi possono essere utilizzati per separare gli oggetti in un numero qualunque di cluster.
Cluster Analysis VS Classificazione
Definito in questo modo il cluster assomiglia molto a un’altra famosa attività della famiglia del Machine Learning: la classificazione. Anche una classe raccoglie al suo interno una serie di oggetti aventi caratteristiche in comune; la differenza sta principalmente nella tecnica utilizzata per definire di quale gruppo faccia parte un determinato oggetto.
Quando si effettua una classificazione si hanno una serie di classi (categorie) note a priori e lo scopo è quello di capire a quale gruppo appartenga un oggetto osservando il valore dei suoi attributi. Per fare questo, durante la fase di addestramento di un modello di classificazione, si parte da un insieme di oggetti dei quali si conosce già la categoria di appartenenza. Attraverso l’analisi degli attributi degli oggetti appartenenti a una determinata classe si cerca di trovare un pattern comune. La classificazione è, quindi, un procedimento di apprendimento supervisionato dove la conoscenza di una determinata categoria esiste a prescindere dagli oggetti in essa raggruppabili.
Nel clustering, invece, l’obiettivo è quello di individuare un certo numero di gruppi in cui è possibile separare gli oggetti di un insieme analizzando i valori dei loro attributi. In questo caso non esistono classi predeterminate né esempi che le rappresentino. L’algoritmo deve riuscire a identificare gli oggetti che “si somigliano” e raggrupparli tra loro. Di conseguenza il clustering è un algoritmo di tipo non supervisionato.
Un esempio di Cluster Analysis per il business
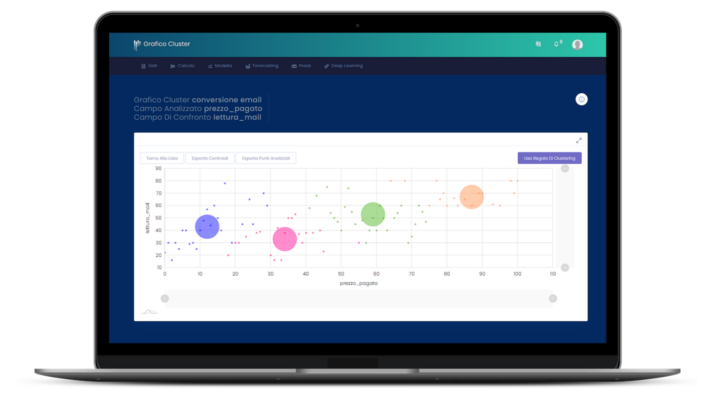
Per esempio, immaginiamo di voler capire quali tra i clienti di un supermercato che dispongono di una carta fedeltà siano ricettivi alle offerte realizzate per stimolare l’acquisto di frutta e verdura. L’aggettivo “ricettivo” è di immediato impatto dal punto di vista comunicativo, ma non esprime un concetto preciso. Tre persone diverse avranno quasi certamente tre metri di giudizio differenti sul tema. Inoltre, pur avendo davanti un cliente non è sufficiente guardarlo per capire se è ricettivo e quanto lo è. In casi come questo, è necessario fare un passo in avanti rispetto ad analisi sommarie e qualitative, andando ad utilizzare approcci metodologici come algoritmi di Clustering. Questi algoritmi, che possono essere di Machine Learning o meno, permettono di suddividere la base dati in un indefinito numero di insiemi rispetto a determinati criteri.
Nel nostro esempio della ricettività in un supermercato, per realizzare un’analisi di questo tipo, è necessario collezionare alcuni dati basi sul cliente come:
- Fascia d’età
- Sesso
- Acquisti ricorrenti
- Valore dello scontrino medio
- Frequenza di acquisto
- ..
Fascia d’età e sesso sono già dei cluster, ma in questo caso rappresentano degli input del problema da risolvere. E qual è l’output dell’algoritmo? Nel nostro caso sarà associare ogni combinazione delle variabili viste sopra ad un certo livello di ricettività alle offerte, ad esempio:
- Fascia di età: 35-40 anni
- Sesso: maschio
- Acquisti ricorrenti: ortaggi e frutta fresca di stagione
- Valore dello scontrino medio: 30€
- Frequenza di acquisto: 1 volta a settimana
- …
In base a tali caratteristiche all’utente viene assegnato uno score di ricettività pari a 3. Ma cosa si intende per 3? Immaginando una classifica di ricettività, questa fascia di clientela ha un livello più marcato di chi ha 1 e 2 ma meno di chi ha 4 o 5. In riferimento a questo esempio, molto è determinato dall’ampiezza e dal numero di cluster in cui viene suddiviso il set di dati. Proprio questa è una delle decisioni che deve prendere l’analista prima di eseguire l’algoritmo. Potrebbe avere l’esigenza (magari dettata dal Marketing), di clusterizzare la clientela in 5 sottoinsiemi, oppure potrebbe voler lasciare l’algoritmo libero di decidere il numero di cluster che meglio descrive la realtà.
Cluster Analysis, il K-means
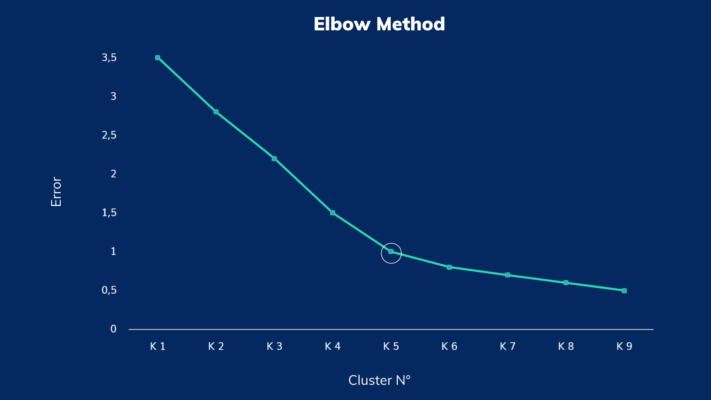
In seguito alla pulizia e alla preparazione dei dati di input, l’analista può scegliere di utilizzare algoritmi che non utilizzano il Machine Learning, come il K-means, che prevede la definizione in anticipo del numero di Cluster che si desidera identificare. Il K-means si basa sull’identificazione dei cosiddetti centroidi. Ogni centroide rappresenta il punto appartenente allo spazio delle features che media le distanze tra tutti i dati appartenenti al cluster ad esso associati. Rappresenta quindi una sorta di baricentro del cluster. Esistono però alcune procedure, come l’Elbow Method, che prevedono l’esecuzione di algoritmi come il K-means per un numero di cluster via via crescente. Questo metodo consente di identificare il numero ottimo di cluster, considerando il giusto equilibrio tra metrica di errore e numerosità dei cluster.
Allo stesso modo si possono usare anche algoritmi di Machine Learning come le Reti Neurali in modalità classificativa, imponendo in anticipo il numero di cluster desiderato.
L’aspetto interessante di tutti gli approcci visti sopra (non si tratta di un’esplorazione esaustiva), è che la numerosità e i confini di questi cluster possono variare nel tempo. Mediante l’acquisizione di nuovi dati e l’aggiunta di informazioni con un maggior livello di dettaglio, è possibile in automatico il nuovo numero di cluster in grado di meglio descrivere la realtà presa in esame.